MySQL
und Unicode. Eine Problemlösung
MySQL und der Wunsch, Unicode in der Datenbank zu speichern und danach -- beim Abruf der Daten -- wieder so vorzufinden, wie man sie eingegeben oder hineinkopiert hat, wird nicht selten ein Unterfangen, das den Nutzer zur Verzweiflung bringen kann. Dabei tauchen nicht erst Probleme mit exotischen Zeichensätzen auf, sondern leider auch schon bei Verwendung der deutschen Sprache: ich meine Probleme mit den deutschen Umlauten ä, ö, ü.
Probleme von MySQL mit Unicode scheinen bekannt; ich selbst habe mehrere Tage im Netz nach Problembeschreibungen und -lösungen gesucht, fand allerdings eher Teillösungen eines -- wie ich mittlerweile meine -- wohl eher generellen Problems, das MySQL zu haben scheint. Darum gebe ich jetzt hier drei einfache Tipps für die Arbeit mit MySQL auf der Ebene seiner GUIs für den MySQL Server 5.0:
- 1. Default-Zeichensatz ändern.
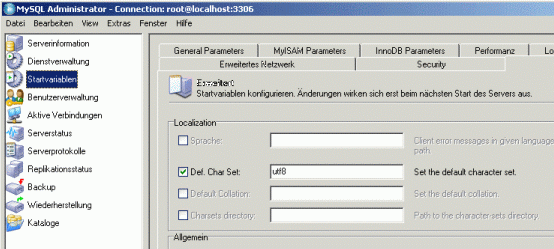
- Die Arbeit mit Unicode in MySQL steht und fällt mit dessen werksmäßig voreingestelltem Zeichensatz, der sich tief in dessen System verbirgt. Dieser Default-Zeichensatz ist "latin1". Wer mit den grafischen Oberflächen (GUI) von MySQL arbeitet -- dem MySQL Administrator und dem MySQL Query Browser -- der logge sich in Ersteren als root ein, gehe auf das Icon "Startvariablen" und dort auf den Reiter "Erweitert" und ändere dort unter "Def. Char Set" die Voreinstellung von "latin1" auf "utf8" und aktiviere die Checkbox, falls dort nicht schon ein Häkchen gesetzt ist. Anschließend ist zu speichern durch Klick auf "Anwenden".
- 2. Rechner neu starten.
- Wer den Rechner nach dieser Einstellungsänderung nicht neu startet, wird nie in den Genuss ordentlicher Unicode-Daten kommen.
- 3. Neue Tabelle(n) erstellen.
- Nun hat es auch keinen Sinn, die Zeichensätze der alten Tabellen oder einzelnen Spalten dieser Tabellen zu ändern, indem man sie auf Unicode sprich auf utf-8 setzt. Selbst wenn MySQL nicht protestieren sollte, ergeben Abfragen in Bezug auf eine Vielzahl von Zeichen Kauderwelsch u.a. eben auch die der Umlaute, selbst wenn sie im MySQL-Browser nach der Abfrage
SELECT * FROM databasename.beliebigetabelle;
- richtig angezeigt werden. Spätestens bei der Abfrage
SELECT * FROM databasename.tabellewieobenWHERE beliebigespalte LIKE '%ü%';
- erhalten wir auch Datensätze in denen kein "ü", dafür aber ein "u" enthalten ist und umgekehrt: Wenn wir statt des "ü" ein "u" bei der Suche angeben, erhalten wir auch den Datensatz ohne "u", sofern er ein "ü" enthält. Selbiges gilt für "ä" und "a" und für "ö" und sein Pendant "o".
- Tipp Nummer 3 lautet also: Wer bestehende Tabelleninhalte mit Unicode wieder- oder weiterverwenden will, hat keine andere Wahl als die Datenbestände aus den alten Tabellen in die neu erstellte(n) Unicode-Tabelle(n) durch Copy und Paste zu überführen oder z.B. seine Altdaten in Textdateien zu konvertieren, die ihrerseits als UTF-8 abzuspeichern sind. Dann können diese über LOAD DATA INFILE in die neu angelegte Tabelle eingespielt werden.
Für Konsolenfreaks und Leute, die Probleme mit Unicode in MySQL in Verbindung mit PHP haben, verweise ich auf die Seite von Gerd Riesselmann, die auch mir weitergeholfen und auf die Spur gebracht hat:
http://www.gerd-riesselmann.de/softwareentwicklung/php-und-utf-8-eine-anleitung-teil-1-mysql
© Lutz Rosemann
______________________________________
letzte Änderung: 1.07.2011